

Kafka
简介
Kafka是一个开源分布式事件流平台,由 Scala 和 Java 编写(运行它需要 Java 环境)。Zookeeper 是 Kafka 早期架构中的“大脑和通讯官”,负责 broker 协调、控制器选举和元数据存储等,现在它逐步被 KRaft 架构取代,最新的kafka 4.0 版本已经完全脱离 ZooKeeper,默认以 KRaft 模式运行。
目前 kafka 几乎都是配合 zk 一起安装的,步骤稍繁琐,为了快速学习,直接安装最新版 kafka 4.0。推荐使用 Docker 安装kafka集群。
基本概念
主题(Topic)
可以把主题 Topic 理解为一个分类箱,生产者(Producer)把消息发送到某个 Topic,消费者(Consumer)从 Topic 中拉取消息。
Broker
Broker 就是一个 Kafka 节点(消息服务器),负责接收、存储和转发消息。
分区(Partition)
分区是 kafka 用来对数据进行分片(一个 Topic 的数据被分散到多个 Broker 中)的一种手段,每个 Topic 中可以有多个分区。多个消费者通过并发访问不同 Broker ,实现消息负载均衡。
副本(replica)
每个分区有多个副本,这些副本被分布保存到不同的 Broker 中,以提高可用性和容错性。一个分区(Partition)在任何时候,只有一个 Broker 上的副本是 Leader 副本(仅读写),其他副本被标记为 follower 副本(仅备份)。
消费者组(Consumer Group)
一个消费者组共同消费一个 Topic 中多个分区的消息,每个消费者组中的成员不会重复消费同一个分区的数据(一个消费者可以同时消费多个分区,一个分区在同一时刻,只能被同一个消费者组内的一个消费者消费)。对于两个不同的消费者组,他们之间相互独立,即它们消费相同的 Topic ,消息互不影响。
控制器(Controller)
选举领导者(Broker)的服务器,负责维护整个 Kafka 集群的状态,并且负责管理 Topic 的增加和 Broker 的新增、删除和故障转移。在 4.x 之前,Kafka 以 ZooKeeper 作为控制器,之后使用 KRaft 模式替代它。
主题
使用 Kafaka ui 创建主题时,需要指定几个重要参数:
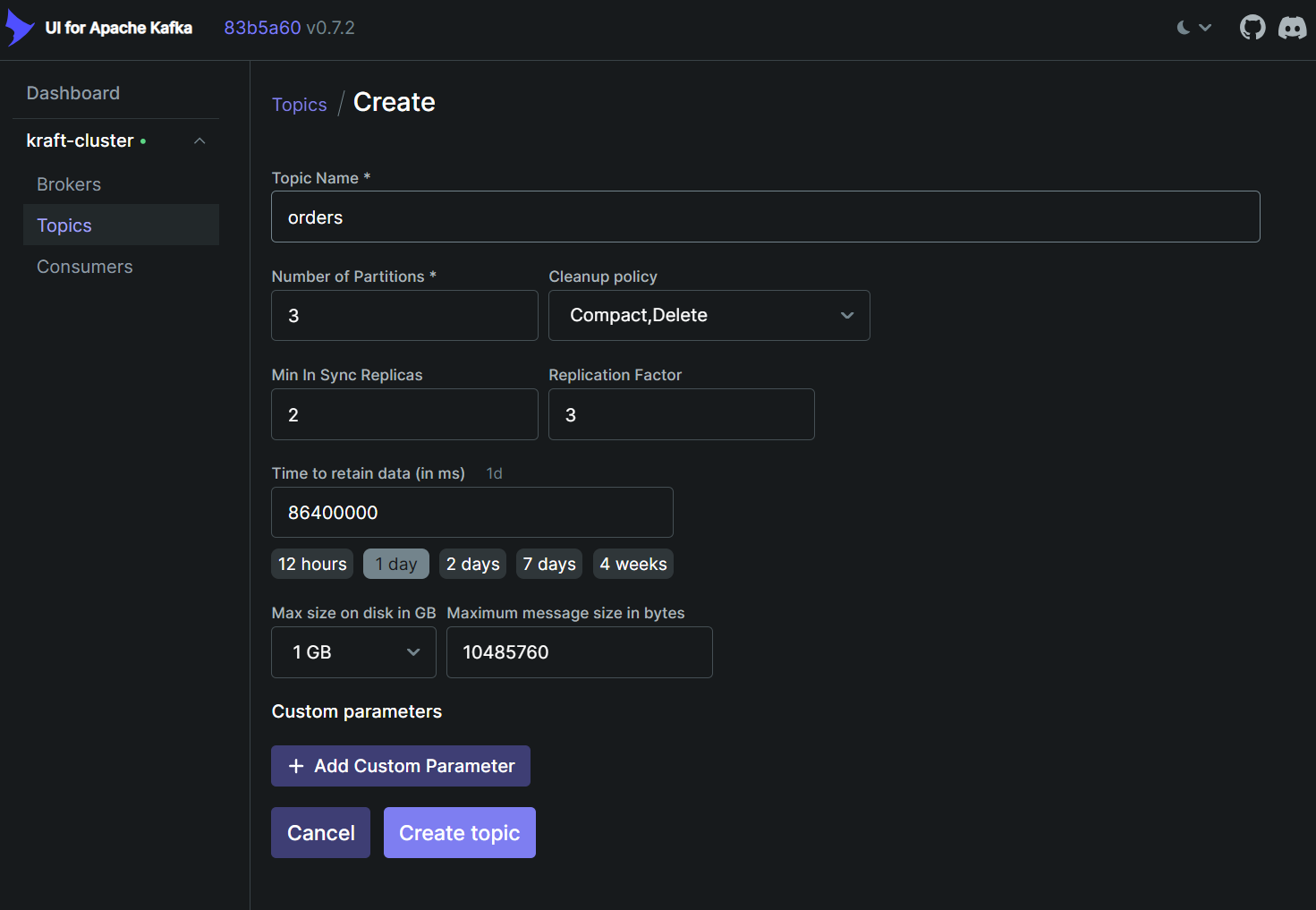
也可以用命令行方式创建主题,以下命令行和上图等效:
kafka-topics.sh --create \
--bootstrap-server localhost:9092 \ # 可指定集群中任意一个Broker,Kafka会自动与集群协调
--topic orders \
--partitions 3 \
--replication-factor 3 \ # 副本数
--config min.insync.replicas=2 \ # 最小同步副本数
--config retention.ms=86400000 \ # 数据保留1天(86400000ms=24小时),默认7天
--config cleanup.policy=compact,delete \ # 混合策略:压缩Key(相同Key只保留最新数据)+按时间/大小删除,默认delete
--config retention.bytes=1073741824 \ # 单个分区最大1GB(1073741824bytes),超过优先删除旧消息;默认无限制
--config max.message.bytes=10485760 # 单条消息最大10MB(10485760bytes),超过无法发送;默认1M| 参数 | 说明 |
|---|---|
| --create | 指定创建主题 |
| --topic | 指定主题名称 |
| --partitions | 指定该主题拥有多少个分区;一个分区只能被同一消费者组内的一个实例消费,分区数量会直接影响到吞吐量、并行度等,建议分区数 = 3 × Broker 数量,后续根据业务适当调整 |
| --replication-factor | 指定每个分区都有多少份副本(包含 Leader + 所有 Follower);推荐值为 3 |
| min.insync.replicas | 指定每个分区最小同步副本;本例中副本为3,最小同步副本为2,表示容忍一个节点故障 |
| --bootstrap-server | 可以指定集群中任意一个 Broker,Kafka 会自动与集群协调 |
提示
- 无需过多考虑 min.insync.replicas 的值该怎么去定义,生产环境中,副本数=3 + 最小同步副本=2 + acks=all 是生产环境黄金组合,其中 acks=all 是消息生产者的一项配置,表示需要所有副本确认,才算生产成功,详见下文整合 SpringBoot 配置文件中的 acks 配置项;
- 注意控制消费者实例数量,通常消费者数量 ≤ 主题分区数
整合 SpringBoot
本节源码:cnb.cool
配置
<!-- Spring Boot Kafka 支持,以下依赖版本都被 SpringBoot 管理,无需指定 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- 可选依赖:kafka-streams 主要用于处理消息运算,和 Java Stream 操作集合类似,只是它操作的是消息 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
<!-- Jackson 序列化 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<!-- Jackson Java 8 时间模块支持 -->
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>server:
port: 8080
spring:
application:
name: kafka-demo
kafka:
bootstrap-servers: 198.168.0.2:9092,198.168.0.2:9094,198.168.0.2:9095 # 多 broker 保证高可用
# ================== 生产者配置 ==================
producer:
retries: 5 # 发送失败重试次数,重试可能使消息重复发送,可通过下面的开启幂等性配置解决
acks: all # all 表示等待所有副本确认才算真正发送成功;0 表示不用等待任何确定;1 表示仅 Leader 确认
batch-size: 16384 # 批量发送的大小(根据业务吞吐量可调整)
buffer-memory: 33554432 # 缓冲区大小(32MB缓冲区,生产环境常见值)
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
compression-type: snappy # 压缩方式,生产环境建议 snappy/lz4
properties:
linger.ms: 10 # 延迟发送,增加批量效率
enable.idempotence: true # 开启幂等性,避免重试产生重复数据和数据乱序,使用事务消息必须开启
# 事务上下文标识前缀,使用事务,这个配置必须设置;以"-"结尾,Spring Kafka会自动为生产者实例生成随机后缀,以避免多实例(单个应用多实例部署)事务冲突
# !!! 一定别忘了结尾的"-",不然就表示固定值,如果被部署成多个实例,但是他们使用了同一事务id,会造成非常严重的事务冲突
transactional.id: ${spring.application.name}-${HOSTNAME}-tx-
transaction.timeout.ms: 60000 # 默认60秒,根据业务调整
interceptor.classes: "com.zhiruan.kafka.demo.config.interceptor.MyProducerInterceptor" # 自定义拦截器
# ================== 消费者配置 ==================
consumer:
group-id: my-consumer-group # 默认消费者组 id,若在 @KafkaListener 注解中没有明确指定 groupId 属性,默认就是这里的值
enable-auto-commit: false # 关闭自动提交;事务场景必须关闭自动提交
# auto-offset-reset 决定了当消费者组消费的处理策略,offset 偏移量可简单理解为游标,记录消息消费到哪里了
# earliest 从第一条消息开始消费(处理所有积累的未过期的消息)
# latest 从最新偏移量消费(跳过中间数据)
# none 简单粗暴,偏移量越界或过期被删除直接报错,运维成本高,某条消息消费异常,直接不提供服务
auto-offset-reset: earliest # 从第一条消息开始消费(处理所有积累的未过期的消息,offset 丢失可能会重复消费)
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer # 注意消费者需要使用反序列化
properties:
spring.json.trusted.packages: "*" # 信任所有包
isolation.level: read_committed # 只读取已提交事务消息
listener:
ack-mode: manual # 手动确认消息
concurrency: 3 # 默认消费者线程数量,若在 @KafkaListener 注解中没有明确指定 concurrency 属性,默认就是这里的值(建议 ≤ 分区数);/**
* 使 jackson 支持JDK 8 LocalDateTime 属性序列化
*/
@Configuration
public class JacksonConfig {
@Bean
public ObjectMapper objectMapper() {
ObjectMapper mapper = new ObjectMapper();
// 支持 Java 8 LocalDateTime 时间类
mapper.registerModule(new JavaTimeModule());
// 避免时间戳
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
return mapper;
}
}/**
* 生产者耗时监控拦截器示例 - 可选配置
* 唯一功能:记录并打印消息发送耗时
*/
@Slf4j
public class MyProducerInterceptor<K, V> implements ProducerInterceptor<K, V> {
/** 消息唯一ID -> 发送开始时间 */
private final ConcurrentHashMap<String, Long> sendStartTimes = new ConcurrentHashMap<>();
@Override
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> producerRecord) {
// 如果消息是 KafkaMessage 类型,则使用 messageId 作为唯一标识
if (producerRecord.value() instanceof KafkaMessage<?> kafkaMessage) {
String msgId = kafkaMessage.getMessageId();
if (msgId != null) {
sendStartTimes.put(msgId, System.currentTimeMillis());
}
}
return producerRecord;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (metadata == null) return;
// 因为 ProducerRecord headers 在 RecordMetadata 中不可用,依然需要遍历 map
sendStartTimes.forEach((msgId, startTime) -> {
long latency = System.currentTimeMillis() - startTime;
log.info("消息发送耗时: {}ms | messageId={} | topic={} | partition={} | offset={}",
latency,
msgId,
metadata.topic(),
metadata.partition(),
metadata.offset());
// 移除已记录的 startTime
sendStartTimes.remove(msgId);
});
}
@Override
public void close() {
sendStartTimes.clear();
log.info("生产者耗时拦截器已关闭");
}
@Override
public void configure(Map<String, ?> configs) {
// 可从配置读取开关或阈值
}
}生产者
@Slf4j
@Service
@RequiredArgsConstructor
public class ProducerService {
private final KafkaTemplate<String, Object> kafkaTemplate;
/**
* 单条消息通用消息发送方法(支持事务 + 异步回调)
*
* @param topicName 主题名称
* @param msg 消息实体
* @param <T> 泛型业务类型,必须可序列化
*/
public <T extends Serializable> void send(String topicName, KafkaMessage<T> msg) {
// 开启事务(executeInTransaction 是同步的)
kafkaTemplate.executeInTransaction(operations -> {
this.sendOperation(operations, topicName, msg);
return true; // 给事务随便返回一个值,它就是 executeInTransaction 方法的结果,本例中没啥用
});
log.debug("生产者已提交事务,topic={} bizKey={}", topicName, msg.getBizKey());
}
/**
* 批量消息通用消息发送方法(支持事务 + 异步回调)
*
* @param topicName 主题名称
* @param msgs 消息实体集合
* @param <T> 泛型业务类型,必须可序列化
*/
public <T extends Serializable> void sendBatch(String topicName, List<KafkaMessage<T>> msgs) {
kafkaTemplate.executeInTransaction(operations -> {
for (KafkaMessage<T> msg : msgs) {
this.sendOperation(operations, topicName, msg);
}
return true; // 返回值无关事务
});
log.debug("生产者已提交批量事务,topic={} 条数={}", topicName, msgs.size());
}
private void sendOperation(KafkaOperations<String, Object> operations, String topicName, KafkaMessage<?> msg) {
// 异步发送消息( send 方法是异步的,返回 CompletableFuture )
CompletableFuture<SendResult<String, Object>> future = operations.send(topicName, msg.getBizKey(), msg);
// 添加回调处理
future.whenComplete((result, ex) -> {
if (ex == null) this.sendSuccess(result, msg);
else this.sendError(msg, ex);
});
}
private <T extends Serializable> void sendSuccess(SendResult<String, Object> result, KafkaMessage<T> msg) {
RecordMetadata metadata = result.getRecordMetadata();
log.debug("消息 bizKey={} 发送成功,topic={} partition={} offset={}",
msg.getBizKey(),
metadata.topic(),
metadata.partition(),
metadata.offset());
}
private <T extends Serializable> void sendError(KafkaMessage<T> msg, Throwable ex) {
log.error("批量消息 bizKey={} 发送失败,原因:{}", msg.getBizKey(), ex.getMessage(), ex);
// kafkaTemplate.send(topicName + ".DLQ", orderMsg.getBizKey(), orderMsg); // 可以尝试重发或加入死信队列
}
}// 通用 Kafka 消息实体;用于封装业务数据和通用元信息,便于日志追踪、幂等控制、调试等
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class KafkaMessage<T extends Serializable> implements Serializable {
@Serial
private static final long serialVersionUID = 1L;
/**
* 消息唯一ID(用于幂等控制、日志追踪)
*/
@Builder.Default
private String messageId = UUID.randomUUID().toString();
/**
* 业务唯一标识(如订单ID、用户ID等)
*/
private String bizKey;
/**
* 消息类型(如 ORDER_CREATED, PAYMENT_SUCCESS 等)
*/
private String messageType;
/**
* 发送方系统标识(方便多系统追踪来源)
*/
private String source;
/**
* 消息发送时间
*/
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@Builder.Default
private LocalDateTime sendTime = LocalDateTime.now();
/**
* 扩展元信息(可以放 TraceId、版本号、操作人等)
*/
private Map<String, Serializable> headers;
/**
* 业务数据(泛型)
*/
private T payload;
}@Slf4j
@SpringBootTest
class KafkaDemoApplicationTests {
private static final String ORDER_TOPIC = "orders";
private final ProducerService producerService;
@Autowired
public KafkaDemoApplicationTests(ProducerService producerService) {
this.producerService = producerService;
}
@Test
void sendOrder() {
Order order = new Order("00", "zs 的订单", 1, new BigDecimal("12.99"), LocalDateTime.now());
KafkaMessage<Order> orderMsg = KafkaMessage.<Order>builder()
.bizKey(order.getOrderId())
.messageType("ORDER_CREATED")
.source("order-service")
.payload(order)
.build();
producerService.send(ORDER_TOPIC, orderMsg);
}
@Test
void sendBatchOrder() {
List<KafkaMessage<Order>> orderList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Order order = new Order("00" + i, "zs 的订单", i, new BigDecimal("12.99"), LocalDateTime.now());
KafkaMessage<Order> orderMsg = KafkaMessage.<Order>builder()
.bizKey(order.getOrderId())
.messageType("ORDER_CREATED")
.source("order-service")
.payload(order)
.build();
orderList.add(orderMsg);
}
producerService.sendBatch(ORDER_TOPIC, orderList);
}
}消费者
// 消费者;不同组消费同一主题,他们完全隔离互不影响
@Slf4j
@Service
public class ConsumerService {
@KafkaListener(
topics = "orders",
groupId = "order-consumer-group-a",
concurrency = "3" // 启动 3 个消费者线程,相当于创建了 3 个消费者实例;
)
public void consumeOrder(ConsumerRecord<String, KafkaMessage<Order>> consumerRecord, Acknowledgment ack) {
long threadId = Thread.currentThread().getId();
KafkaMessage<Order> orderMsg = consumerRecord.value();
log.info("消费者线程{}收到订单: {},开始处理业务...", threadId, orderMsg.getPayload());
ack.acknowledge(); // !!!手动提交 offset,保证消息真正被消费
log.info("{}业务处理完成,手动通知 kafka 已完成消费...", threadId);
}
@KafkaListener(
topics = "orders",
groupId = "other-group",
concurrency = "1"
)
public void consumeOther(ConsumerRecord<String, KafkaMessage<Order>> consumerRecord, Acknowledgment ack) {
KafkaMessage<Order> orderMsg = consumerRecord.value();
log.info(" other-group 收到订单: {},开始处理业务...", orderMsg.getPayload());
ack.acknowledge(); // !!!手动提交 offset,保证消息真正被消费
}
}