

oracle基础
简介
Oracle Database 19c 在 2019 年发布,且作为长期支持版(至少到 2027 年),经过长时间的大规模部署验证,是许多企业生产环境中的首选(目前的 21C 版本是创新版,可能会有更多的 bug )。
以开发或学习目的部署 Oracle 数据库,可以访问所有 Oracle Database 19c 的特性,没有功能上的限制。但是如果需要上生产,就必须购买授权。
Oracle 数据库下载地址,注意 Windows 系统家庭版不支持安装 Oracle 数据库,详见官网。
使用 Docker 安装的 Oracle,完全能够满足学习需求。
通过 Docker Compose 创建了一个 SID(数据库实例的唯一标识) 为 orcl 的容器数据库(CDB),和一个名为 orclpdb 的 PDB(可插拔数据库),在 CDB 中能创建多个 PDB,它们是相互独立的数据库。
当第一次使用 Oracle 数据库时,比较规范的操作顺序为:创建库->创建表空间->创建用户并指定到表空间->创建表,一个库中可以创建多个用户,用户创建的表相互隔离互不影响;下面章节将演示这些过程。
创建库
创建 PDB 就相当于创建了一个新的数据库,新建的 PDB 库中,超级管理员也是 SYS,密码和 CDB 一致;
# 登录到 CDB 并建立新的 PDB (sqlplus是Oracle自带的远程连接工具)
# sys 用户中权限最高,必须要加上 as sysdba 才能连接
sqlplus sys/root@localhost:1521/orcl as sysdba;
# 新建 my_pdb 库并绑定一个名为 my_test_pdb_user 的管理员用户;
# 管理员用户是一个具有 DBA 权限的用户,不需要手动为该用户额外绑定表空间。
# FILE_NAME_CONVERT 用于文件名转换,若不指定,每个新建的 PDB 文件都会保存在 ORCLPDB 这个目录,不便于管理
CREATE PLUGGABLE DATABASE my_pdb ADMIN USER my_test_pdb_user IDENTIFIED BY my_password FILE_NAME_CONVERT = ('/opt/oracle/oradata/ORCL/', '/opt/oracle/oradata/MY_PDB/');
# 打开新创建的 PDB
ALTER PLUGGABLE DATABASE my_pdb OPEN;
# 查看 PDB 状态,为 READ WRITE,表示已打开
SELECT name, open_mode FROM v$pdbs;
# 保存 PDB 的状态,重启时会自动打开
ALTER PLUGGABLE DATABASE my_pdb SAVE STATE;
# 测试连接
sqlplus my_test_pdb_user/my_password@localhost:1521/my_pdb;sqlplus sys/root@localhost:1521/orcl as sysdba;
ALTER PLUGGABLE DATABASE my_pdb CLOSE IMMEDIATE;
# INCLUDING DATAFILES 表示同时删除与 PDB 相关的数据文件,若要保留文件可忽略此参数
DROP PLUGGABLE DATABASE my_pdb INCLUDING DATAFILES;
# 查看 PDB 状态
SELECT name, open_mode FROM v$pdbs;创建表
创建好了数据库,下面演示 创建表空间->创建用户并指定到表空间->创建表 的过程。单个用户可以绑定多个表空间。
sqlplus sys/root@localhost:1521/my_pdb as sysdba;
# 建立一个初始大小 50M,每次自动扩容 10M,最大容量 500M的名为 my_tbs 的表空间
# 常用容量单位有 M、G、T 等
CREATE TABLESPACE my_tbs DATAFILE '/opt/oracle/oradata/MY_PDB/my_tbs01.dbf' SIZE 50M AUTOEXTEND ON NEXT 10M MAXSIZE 500M EXTENT MANAGEMENT LOCAL;sqlplus sys/root@localhost:1521/my_pdb as sysdba;
# 方式一:将新建的 my_tbs_user 用户和 my_tbs 表空间绑定
# 说明:temp 是系统自带的一个临时表空间,用于存储查询过程中的临时数据(如ORDER BY、GROUP BY等),可以提升一定性能
CREATE USER my_tbs_user IDENTIFIED BY my_password DEFAULT TABLESPACE my_tbs TEMPORARY TABLESPACE temp;
# 授权,允许用户连接到数据库。允许创建表、序列等
GRANT CONNECT, RESOURCE TO my_tbs_user;
GRANT CREATE VIEW TO my_tbs_user; # 允许创建视图
# GRANT DBA TO my_tbs_user; 最高授权
# 配额,允许用户在表空间中可以使用磁盘空间,UNLIMITED 表示无限制
ALTER USER my_tbs_user QUOTA UNLIMITED ON my_tbs;
# 方式二:将已存在的其他用户和 my_tbs 表空间绑定
ALTER USER other_user DEFAULT TABLESPACE my_tbs;
ALTER USER other_user TEMPORARY TABLESPACE temp;
# 授权、配置略
...
# 查询用户的默认表空间(用户名需要大写字母)
SELECT username, default_tablespace FROM dba_users WHERE username = 'MY_TBS_USER';# 使用新用户登录
sqlplus my_tbs_user/my_password@localhost:1521/my_pdb;
# 创建表
CREATE TABLE my_test_tables (id NUMBER(10) PRIMARY KEY,name VARCHAR2(50),created_date DATE);
INSERT INTO my_test_tables VALUES (1, 'ZS', TO_DATE('2024-09-18', 'YYYY-MM-DD'));
SELECT * FROM my_test_tables;# 删除表
DROP TABLE my_test_tables;
# 删除用户
DROP USER my_user CASCADE;
# 删除表空间
DROP TABLESPACE my_tbs INCLUDING CONTENTS AND DATAFILES;
# 删除当前用户创建的所有表
BEGIN
FOR t IN (SELECT table_name FROM user_tables) LOOP
EXECUTE IMMEDIATE 'DROP TABLE ' || t.table_name || ' CASCADE CONSTRAINTS';
END LOOP;
END;
# 删除当前用户创建的所有视图
BEGIN
FOR v IN (SELECT view_name FROM user_views) LOOP
EXECUTE IMMEDIATE 'DROP VIEW ' || v.view_name;
END LOOP;
END;表授权
在 Oracle 中,不同用户(或模式)之间的对象(如表)默认情况下是相互隔离的。这意味着,某个用户创建的表只对该用户可见。
如果想让其他用户操作自己的表,则需赋予相应的权限来使使他们共享数据。
假设 my_tbs_user 创建了一张表,需要执行如下 SQL 语句来授予 my_test_pdb_user 用户对于该表的 CRUD 权限:
逐个表授权
若只想赋予少量表的权限给单个用户,可以使用如下方法:
-- 以 my_tbs_user 身份登录,授予 my_test_pdb_user 权限 grant all on my_table to my_test_pdb_user; -- 仅包括表的 CRUD 操作、索引、外键 grant create table to my_test_pdb_user; -- 创建表 grant drop on my_table to my_test_pdb_user; -- 删除表 grant alter on my_table to my_test_pdb_user;-- 修改表多个表同时授权
若想将多张表的权限授予多个用户,可以使用授权角色的方法:
-- 一般使用 sys 用户或其他具有管理权限的用户来创建角色 -- 创建角色 create role my_role; -- 授予该角色相应权限 grant create any table to my_role; -- 创建表 grant alter any table to my_role; -- 修改表 grant drop any table to my_role; -- 删除表 begin for rec in (select table_name from all_tables where owner = 'my_tbs_user') loop execute immediate 'grant all on ' || rec.owner || '.' || rec.table_name || ' to my_role'; end loop; end; -- 将角色授予 my_test_pdb_user grant my_role to my_test_pdb_user;权限查询
-- 查看所有角色 select role from dba_roles; -- 查看角色的权限 select * from role_tab_privs where role = 'MY_ROLE'; -- 查看用户所拥有的角色 select * from user_role_privs where username = 'MY_TEST_PDB_USER'; -- 查询所有角色权限 select r.role, p.privilege from dba_roles r left join role_sys_privs p on r.role = p.role order by r.role;
使用 Navicat 连接
Oracle 自带的客户端工具 sqlplus 功能强大,但它更适合专业 DBA 使用,使用 Navicat 或 DataGrip 连接 Oracle 对开发工程师更加友好,此处以 Navicat 为例。
下载 Oracle 提供的客户端工具包,解压,并在 Navicat 菜单中点击工具->选项->环境,在 OCI 配置项中指定工具包中的 oci.dll 文件路径。
然后根据下图填写连接信息即可。
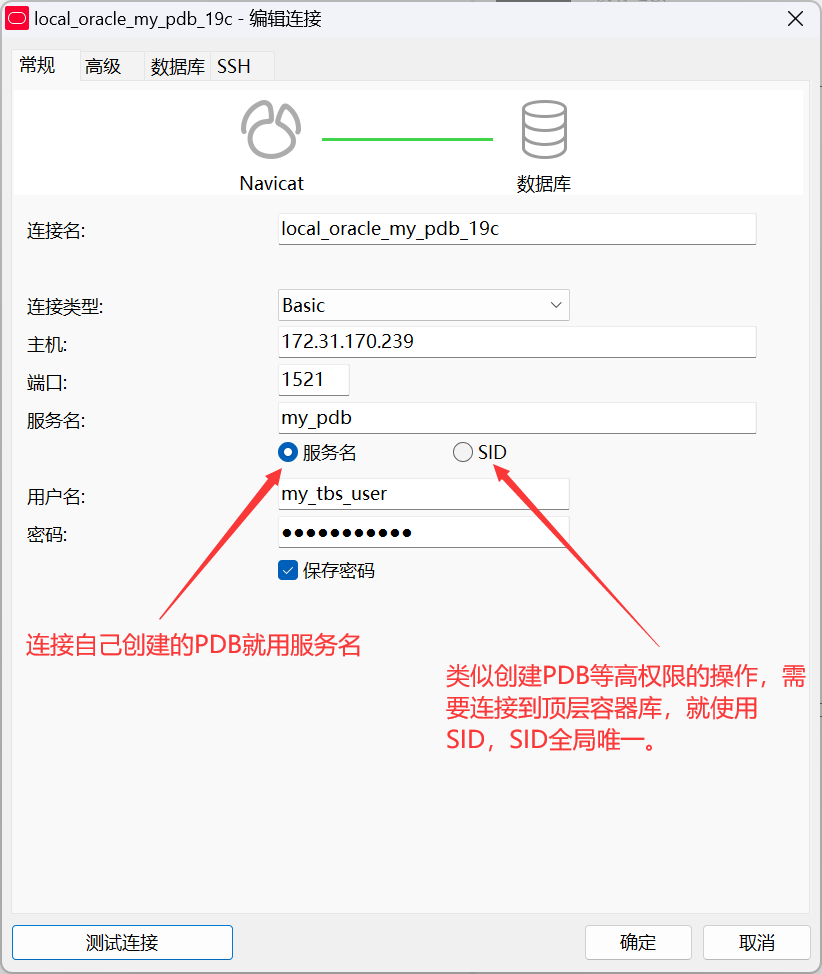
提示
Navicat 使用 sys 用户登录时,需要在高级菜单中将角色选择为 SYSDBA 再登录;DateGrip 使用 sys 用户登录,直接在用户名后写上 as sysdba 即可;
常用操作
查询
-- 查询 oracle 版本号
select * from v$version;
-- 查询所有表
select table_name from user_tables;
-- 查询所有表空间
SELECT tablespace_name FROM dba_tablespaces;插入
将查询结果插入到表中,某些数据迁移场景可能会用到。
-- 对于 school ,表 old_user 中没有这个字段,可以手动给他赋值
insert into user(id, name, school)
select id, old_name as name, '华阳中学' as school from old_user;
-- 根据用户id,将 a 表中的身份证、手机号插入到 b 表(假设 b 表只有用户 id 数据)
update user_shool b
left join user_info a on b.user_id = a.user_id
set b.id_card = a.id_card, b.phone = a.phone
WHERE a.age > 1;分析函数
有如下成绩表,要求根据成绩排名,并附带每个学生名次:
| name | score |
|------|-----------|
| Jack | 98 |
| Tom | 99 |
| Jim | 97 |
| Tim | 97 |
| Iris | 95 |
| Dora | 96 |可使用 rank、dense_rank、row_number 函数实现分析功能,如下:
-- 相同分数排名相同,排名值跳跃
select rank() over(order by score desc) 排名, t.* from t_score t
-- 相同分数排名相同,排名值连续
select dense_rank() over(order by score desc) 排名, t.* from t_score t
-- 相同分数排名不同,排名值连续
select row_number() over(order by score desc) 排名, t.* from t_score t查询结果如下:
| name | score | 排名 |
|------|-----------|------|
| Tom | 99 | 1|
| Jack | 98 | 2|
| Jim | 97 | 3|
| Tim | 97 | 3|
| Dora | 96 | 5|
| Iris | 95 | 6|| name | score | 排名 |
|------|-----------|------|
| Tom | 99 | 1|
| Jack | 98 | 2|
| Jim | 97 | 3|
| Tim | 97 | 3|
| Dora | 96 | 4|
| Iris | 95 | 5|| name | score | 排名 |
|------|-----------|------|
| Tom | 99 | 1|
| Jack | 98 | 2|
| Jim | 97 | 3|
| Tim | 97 | 4|
| Dora | 96 | 5|
| Iris | 95 | 6|时间函数
-- 查询当前时间 -- 例如结果为 date类型的 2024-10-13 23:24:25
select sysdate from dual;
-- 字符转时间,Oracle 中时间格式不区分大小写 -- 结果为 date类型的 2024-10-13 23:24:25
select to_date('20241013 23:24:25','yyyymmdd hh24:mi:ss') from dual;
-- 时间只取年月日 -- 例如结果为 date类型的 2024-10-13
select trunc(sysdate) from dual;
-- 时间获取年月日
select trunc(sysdate,'mm') from dual; -- 只获取月份,结果为 date类型,例如 2024-10-01
select extract(year from date_column) as year from your_table; -- 获取年,结果为 number 类型;year、month、day
select to_char(date_column, 'yyyy') as year from your_table; -- 获取年,结果为 varchar 类型;
-- 计算时间差,两个时间会附带时分秒计算
select sysdate, (sysdate + 1) as plus_one_day from dual; -- 当前时间加上1天
select sysdate + 1 + numtodsinterval(12, 'hour') -- 当前时间加上1天12小时;也可指定分、秒 minute second
- sysdate from dual; -- 结果为1.5; 因为1天12小时 = 1.5天,Oracle中日期运算默认以天为单位
select floor(sysdate + 1 - sysdate) from dual;-- 只取整数天数(忽略小时分钟)
-- 查询过去两天的数据
select * from your_table
where date_column >= trunc(sysdate) - 2
and date_column < trunc(sysdate);
-- 查询某个时段的数据,如 2025 年
select * from your_table
where date_column >= to_date('2025-01-01', 'yyyy-mm-dd')
and date_column < to_date('2026-01-01', 'yyyy-mm-dd');case when
简单使用
若员工表中有员工 id 和薪水两个字段,现想增加一个 salary_level 薪水等级:薪水高于 7K 返回高薪,4k~7K 返回中等薪水,否则低薪。
再增加一个 salary_type 是不是烂仔:低于 3K 是烂仔,否则不是。
select employee_id, salary, -- 定义第一个 case when,用于薪水等级 case when salary > 7000 then '高薪' when salary between 4000 and 7000 then '中等薪水' else '低薪' end as salary_level, -- 定义第二个 case when,用于查询是不是烂仔 case when salary > 3000 then '不是烂仔' else '是烂仔' end as salary_type from employees;配合 count 函数使用
若员工的薪水是多劳多得制度,现在要求根据员工分组,查询高新、中薪、低薪的总发放次数,并计算该员工领取薪水的总次数
select employee_id, count(case when salary > 7000 then 1 end) as high_salary_count, -- 高薪次数 -- 注意 count(case when ... then 1 end) 中的 1 只是个占位符,没有实际意义 count(case when salary between 4000 and 7000 then 1 end) as middle_salary_count, -- 中薪次数 -- 使用 count() 或 sum() 结果都一样 sum(case when salary < 4000 then 1 end) as low_salary_count, -- 低薪次数 count(case when salary between 4000 and 7000 or salary < 4000 then 1 end) as middle_low_salary_count, -- 中薪或低薪次数 count(*) -- 总次数 from employees group by employee_id;配合 having count 使用
假设某药房有如下订单详情表,需求为:1、2 号商品为高风险药品,同一订单中,1 号商品不能超过 1 个,2 号商品不能超过两个,现需验证此药房是否遵循这一约定。
+---------------+--------+----------+ |order_detail_id|order_id|product_id| +---------------+--------+----------+ |1 |1 |1 | |2 |1 |2 | |3 |2 |1 | |4 |3 |8 | |5 |5 |1 | |6 |5 |1 | |7 |5 |2 | +---------------+--------+----------+sqlselect t.order_id, count(case when t.product_id = 1 then 1 end) as prod_one_count, count(case when t.product_id = 2 then 1 end) as prod_two_count from AA_ORDER_DETAIL t group by order_id -- 筛选 1 号超过一个或者 2 号超过两个的订单 having count(case when t.product_id = 1 then 1 end) > 1 or count(case when t.product_id = 2 then 1 end) > 2 order by order_id结果+--------+--------------+--------------+ |order_id|prod_one_count|prod_two_count| +--------+--------------+--------------+ |5 |2 |1 | +--------+--------------+--------------+
分组条件查询
有一如下张表,记录了用户与他们拥有的水果信息:
| name | fruit |
|------|-----------|
| Jack | apple |
| Jack | orange |
| Jack | grape |
| Tom | apple |
| Tom | grape |
| Jim | apple |如果想查询同时拥有 apple 和 grape 的用户,可以按用户分组,在查组内满足条件的数据:
select name
from your_table
group by name
having count(case when fruit = 'apple' then 1 end) > 0
and count(case when fruit = 'grape' then 1 end) > 0;窗口函数
提示
窗口函数可以将不同组视为独立的窗口,并单独执行一些逻辑。有 over 关键字,基本语法为:
<函数名> over (partition by <分组的列> rows between <起始行> and <终止行>)例如打卡表的数据如下:
+--+-------+-------------------+
|id|user_id|punch_time |
+--+-------+-------------------+
|1 |1 |2024-10-01 12:00:00|
|2 |1 |2024-10-02 12:00:10|
|3 |1 |2024-10-03 12:00:20|
|4 |2 |2024-10-01 12:00:10|
|5 |2 |2024-10-03 12:00:20|
|6 |3 |2024-10-02 12:00:10|
+--+-------+-------------------+需求一
计算每个用户的打卡总次数,并追加到每行数据后面
方式一select t.*, count(*) over (partition by user_id) as p_times from user_punch t -- 等效于下面,唯一不同就是下面会在每个窗口给时间排序 select t.*, count(*) over (partition by t.user_id order by t.punch_time rows between unbounded preceding and unbounded following) as p_times from user_punch t结果# 方式一执行结果 +--+-------+-------------------+-------+ |id|user_id|punch_time |p_times| |1 |1 |2024-10-01 12:00:00|3 | |2 |1 |2024-10-02 12:00:10|3 | |3 |1 |2024-10-03 12:00:20|3 | |4 |2 |2024-10-01 12:00:10|2 | |5 |2 |2024-10-03 12:00:20|2 | |6 |3 |2024-10-02 12:00:10|1 | +--+-------+-------------------+-------+方式二select t.*, count(*) over (partition by user_id order by t.punch_time) as p_times from user_punch t; -- 等效于下面 select t.*, count(*) over (partition by t.user_id order by t.punch_time rows between unbounded preceding and current row) as p_times from user_punch t结果# 方式二执行结果 +--+-------+-------------------+-------+ |id|user_id|punch_time |p_times| |1 |1 |2024-10-01 12:00:00|1 | |2 |1 |2024-10-02 12:00:10|2 | |3 |1 |2024-10-03 12:00:20|3 | |4 |2 |2024-10-01 12:00:10|1 | |5 |2 |2024-10-03 12:00:20|2 | |6 |3 |2024-10-02 12:00:10|1 | +--+-------+-------------------+-------+提示
窗口函数的 partition by 不支持添加条件,但可以使用 case when 来间接实现条件分区聚合。如需求改为:分别计算每个用户的打卡总次数和 3 号之前的打卡数,追加到每行数据后面
select t.*, count(*) over (partition by user_id order by t.punch_time) as all_times, count(case when trunc(t.punch_time) < to_date('2024-10-03') then 1 else 0 end) over (partition by user_id order by t.punch_time) as before_times, from user_punch t;需求二
筛选连续打卡少于三天的用户;这个需求就有点难度了,实现方式如下:
sql-- 第二步,将第一步的结果作为【临时结果集】 with temp_punches as ( -- 第一步,使用窗口函数查询每条数据的日期和他上一条相邻的时间 select user_id, punch_time, trunc(punch_time) as current_day, -- 当前打卡时间 trunc(lag(punch_time,1) over (partition by user_id order by punch_time)) as one_ago, -- 前一条打卡时间 trunc(lag(punch_time,2) over (partition by user_id order by punch_time)) as two_ago -- 前两条打卡时间 from user_punch ) -- 第三步,查询临时结果集中,符合条件的数据 select * from temp_punches where current_day - one_ago = one_ago - two_ago; -- 必须符合连续三天第一步结果+-------+-------------------+-----------+----------+----------+ |user_id|punch_time |current_day|one_ago |two_ago | +-------+-------------------+-----------+----------+----------+ |1 |2024-10-01 12:00:00|2024-10-01 |null |null | |1 |2024-10-02 12:00:10|2024-10-02 |2024-10-01|null | |1 |2024-10-03 12:00:20|2024-10-03 |2024-10-02|2024-10-01| |2 |2024-10-01 12:00:10|2024-10-01 |null |null | |2 |2024-10-03 12:00:20|2024-10-03 |2024-10-01|null | |3 |2024-10-02 12:00:10|2024-10-02 |null |null | +-------+-------------------+-----------+----------+----------+第二步结果+-------+-------------------+-----------+----------+----------+ |user_id|punch_time |current_day|one_ago |two_ago | +-------+-------------------+-----------+----------+----------+ |1 |2024-10-03 12:00:20|2024-10-03 |2024-10-02|2024-10-01| +-------+-------------------+-----------+----------+----------+
操作字符
-- 字符拼接
select 'Hello' || 'World' as greeting from dual; -- 注意不能使用 + 拼接字符串
select concat('Hello', 'World') as greeting from dual;
-- 截取
select substr('good boy!', 1, 4) as result from dual; -- 结果为 good
-- 计算长度
select length('Oracle') as result from dual; -- 结果为 6
-- 去除两端空格;如果原始值是 null 或 空格,都返回null
select trim(' Oracle ') as result from dual;
select * from user where phone is not null and trim(phone) is not null; -- 非空判断
-- 字符替换
select replace('Oracle SQL', 'SQL', 'DB') as result from dual; -- 结果为 Oracle DB
-- 字母大写(upper)、小写(lower)、首字母大小(initcap)
select upper('oracle sql') as result from dual;列转行
提示
unpivot 关键字可将指定的列转为行,其基本语法如下:
-- 列名是新的列,用于存放旋转后原先列的数据
-- 标识列是用于记录旋转后每行的数据来自原来的哪个列
-- 列1、列2...是指定哪些列需要被转换成行
unpivot (
<列名> for <标识列> in (<列1>, <列2>, ...)
)举个例子,由于某个毕业生程序员非常菜,设计了如下一个爱好表,假如爱好种类共有 20 种:
| id | name | a_id | a_name | b_id | b_name | c_id | c_name | ... | t_name |
|-----|------|------|--------|------|--------|------|--------| --- | ---- |
| 1 | Jack | 1 | 篮球 | 2 | 足球 | 3 | 羽毛球 | ... | 爬山 |
| 2 | Tom | 1 | 篮球 | 3 | 羽毛球 | 4 | 打架 | ... | |
| 3 | Bob | 1 | 篮球 | 2 | 足球 | 4 | 打架 | ... | |
...现有如下需求:查询每个人的爱好 id 和爱好名,如果有 "打架" 这项爱好的,把他们揪出来。
你看到这样的需求,第一个要骂的肯定是这个菜鸟程序员,但目前表里面的数据量很大,你不得不在这张表的基础上查询。 一个理想的数据集应该是这个样子(便于找到爱好打架人员):
# 所有人的爱好列表,得到如下结果:
| id | name | 爱好id | 爱好名 |爱好名来源列 |
|-----|------|--------|-------|-----------|
| 1 | Jack | 1 | 篮球 | a_name |
| 1 | Jack | 2 | 足球 | b_name |
| 1 | Jack | 3 | 羽毛球 | c_name |
...
| 1 | Jack | 20 | 爬山 | t_name |
| 2 | Tom | 1 | 篮球 | a_name |
| 2 | Tom | 3 | 羽毛球 | b_name |
| 2 | Tom | 4 | 打架 | c_name |
...在 Oracle 中,可以通过列转行实现这个功能;为了方便理解,我们列举两种需求对比:
-- 查询每个人的爱好名,如果有 "打架" 这项爱好的,把他们揪出来
select id,爱好名,爱好名来源列
from hobby
unpivot (
爱好名 for 爱好名来源列 in (
a_name,
b_name,
...
t_name
)
)-- 查询每个人的爱好 id 和爱好名,如果有 "打架" 这项爱好的,把他们揪出来
select id,name,爱好id,爱好名,来源列
from hobby
unpivot (
(爱好id, 爱好名) for 来源列 in (
(a_id, a_name) as 'a_id_name',
(b_id, b_name) as 'b_id_name',
...
(t_id, t_name) as 'c_id_name'
)
)# 结果集
| id | 爱好名 |爱好名来源列 |
|-----|--------|-----------|
| 1 | 篮球 | a_name |
| 1 | 足球 | b_name |
| 1 | 羽毛球 | c_name |
...
| 1 | 爬山 | t_name |
| 2 | 篮球 | a_name |
...# 结果集
| id | name | 爱好id | 爱好名 | 来源列 |
|-----|------|--------|-------|---------------|
| 1 | Jack | 1 | 篮球 | a_id_name |
| 1 | Jack | 2 | 足球 | b_id_name |
| 1 | Jack | 3 | 羽毛球 | c_id_name |
...
| 1 | Jack | 20 | 爬山 | t_id_name |
| 2 | Tom | 1 | 篮球 | a_id_name |
...将结果作为子查询,可轻松找到爱好打架人员!
这里隐藏了一个问题: 如果列非常非常多,会导致 SQL 写着很浪费时间!笔者在某单位上班时遇到过类似需求,表列数高达 200 列,当时人都整麻木了!因此在设计表时一定要合理,给后人留条活路!
行转列
和列转行非常类似,例如有如下数据:
+----------+------+-----+
|department|year |sales|
+----------+------------+
|A |2023 |100 |
|A |2024 |150 |
|B |2023 |200 |
|B |2024 |250 |
+----------+------+-----+现在希望将 year 字段的值作为列名,把销售数据 sales 展开到相应的列中,使结果表如下:
+----------+-----------+-----------+
|department|sales_2023 |sales_2024 |
+----------+-----------+-----------+
|A |100 |150 |
|B |200 |250 |
+----------+-----------+-----------+可以通过 pivot 关键字或 case when 条件聚和 两种方式实现这一效果:
-- 行转列
select *
from sales_data
pivot (
sum(sales) -- 聚合函数
for year in (2023 as sales_2023, 2024 as sales_2024) -- 行转列
);-- 行转列
select
department,
sum(case when year = 2023 then sales end) as sales_2023,
sum(case when year = 2024 then sales end) as sales_2024
from
sales_data
group by
department;集合运算
集合运算用于将两个列数、顺序相同的数据集合并。
-- 并集,两个结果集合并的结果
-- 并集去重必须满足所有字段值相同
select * from user where id < 10
-- union all 不去重
union -- 去重
select * from user where id < 5-- 两个结果集都存在且玩完一样的数据
select * from user where id < 10
intersect
select * from user where id < 5-- 返回左侧有但右侧没有的数据,如下会返回 id 为 5~9 的数据
select * from user where id < 10
minus
select * from user where id < 5关联查询
关联查询(Join Query)用于从多个表中获取相关联的数据。
-- Oracle 的 join 等效于 inner join,只返回两个表中【同时符合】条件的数据。
select * from A inner join B on a.id = b.id;
select * from A a, B b where a.id = b.a_id; -- 旧语法,不推荐使用,和 inner join 等效-- 返回左表所有记录,右表不存在的返回 null;
-- 建议 left join 时小表在左边,因为会优先加载左表到内存,小表更快
select * from A left join B on a.id = b.id;-- 返回右表所有记录,左表不存在的返回 null;
-- 建议 right join 时小表在右边,因为会优先加载右表到内存,小表更快
select * from A left join B on a.id = b.id;-- 返回左表和右表的【所有记录】,没有匹配的记录则返回 null;
select * from A full outer join B on a.id = b.id;-- 返回两个表的笛卡尔积,即返回所有可能的记录组合(数据量为:左表行数 * 右表行数)。
select * from A cross join B;
select * from A, B; -- 和 cross join 等效-- 返回同一张表的两个别名之间的连接,可用于有层级关系的数据,如查询上级数据
select a.id, a.name, b.name as parent_name from A a left join A b on a.id = b.parent_id;注意事项
/** -------------查询 -------------**/
-- 1. not in 中包含 null 值,查询会失效,建议判断空
select id from A where id not in (select id from 表B where id is not null);导入导出
导入导出指令是独立的命令行工具,直接在操作系统的命令行中执行。
expdp 和 impdp
expdp 和 impdp 是 Oracle 推荐的 Data Pump 导出和导入工具,性能优越,支持并行处理。若要指定 dmp 文件目录,需要在 Oracle 数据库中定义一个目录对象,该目录对象映射到操作系统的实际文件系统路径。
-- 以 system 用户连接到数据库
create or replace directory export_dir as '/path/to/dmp/directory';
-- 授予权限给目标用户(例如 system 用户)
grant read, write on directory export_dir to your_user;# 导出整个数据库
expdp system/password@db_name full=y directory=export_dir dumpfile=full_db_export.dmp logfile=full_db_export.log
# 导出特定用户的数据
expdp system/password@db_name schemas=username directory=export_dir dumpfile=user_export.dmp logfile=user_export.log
# 导出特定表的数据
expdp system/password@db_name tables=table1,table2 directory=export_dir dumpfile=table_export.dmp logfile=table_export.log# 导出整个数据库
impdp system/password@db_name full=y directory=import_dir dumpfile=full_db_export.dmp logfile=full_db_import.log
# 导出特定用户的数据
impdp system/password@db_name schemas=username directory=import_dir dumpfile=user_export.dmp logfile=user_import.log
# 导出特定表的数据
impdp system/password@db_name tables=table1,table2 directory=import_dir dumpfile=table_export.dmp logfile=table_import.logexp 和 imp
exp 和 imp 是 传统的命令行工具,适用于较小的数据操作,性能较 expdp 和 impdp 差。exp 和 imp 不需要创建 Oracle 目录对象,而是直接使用操作系统的文件路径来指定 dmp 文件的位置。
# 导出整个数据库
exp system/password@db_name file=/path/to/full_db_export.dmp full=y
# 导出特定用户的数据
exp system/password@db_name file=/path/to/user_export.dmp owner=username
# 导出特定表的数据
exp system/password@db_name file=/path/to/table_export.dmp tables=table1,table2# 导出整个数据库
imp system/password@db_name file=/path/to/full_db_export.dmp full=y
# 导出特定用户的数据
imp system/password@db_name file=/path/to/user_export.dmp fromuser=username touser=new_username
# 导出特定表的数据
imp system/password@db_name file=/path/to/table_export.dmp tables=table1,table2